
The U.S. Supreme Court will hold oral argument in Oracle v. Google on October 7. It’s supposed to be one of the most important copyright cases in decades. Not only will the Supreme Court visit computer programs for the first time since 1996’s Lotus v. Borland, which decided nothing because it was a 4-4 tie, but it will confront fair use directly for the first time since 1994’s notorious “Oh! Pretty Woman” case.
I’ve blogged repeatedly about this case. The most important posts are this one, where I ate humble pie and corrected my own misapprehension about Oracle’s case; this one, where I talk about whether fair use is a jury question or not; and these two, where I criticize the Federal Circuit’s reversal of the jury’s verdict finding fair use. A couple of other good ones are this one about why software needs to be protected by something other than copyright; and this one, about damages, but those are beyond the scope of this post. Please don’t read my early posts, though, because I (along with a lot of other people) was wrong about something fundamental (which I explain here).
Two other useful links: to Federal Circuit’s opinions in Oracle’s first and second appeals.
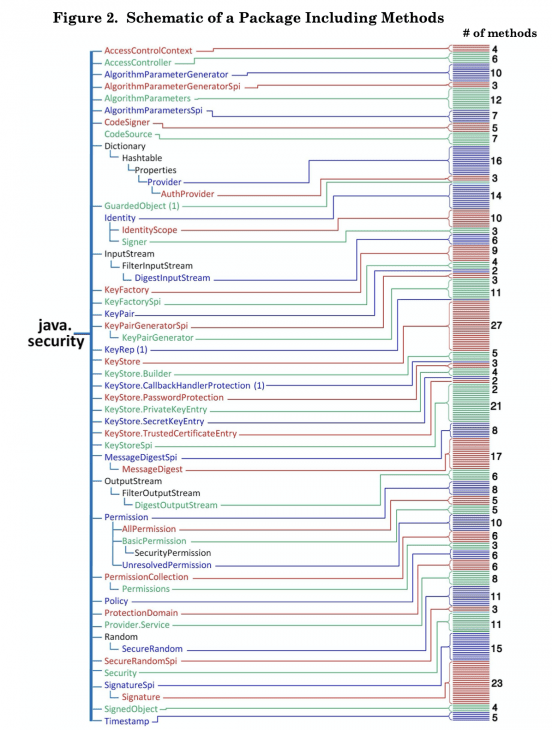
Before I get into the opinionated primer, I’m going to drop in here this chart, which I copied from Oracle’s own brief in the first appeal. This chart is key to understanding what’s going on, and I’ll explain it below.
-
What’s at Stake
- There’s a small but non-trivial chance that copyright protection for software will be gutted. Copyright is still the main way to protect software (though patent and trade secret play important roles), so this would be a significant change. Maybe for the better, maybe for the worse.
- There’s a small but non-trivial chance that fair use will be significantly changed. Since fair use is the main way your right to free expression pushes back against the restrictions imposed by copyright, a major change here would have pretty far-reaching effects.
- There’s a fairly good chance that your ability to assert fair use will be weakened. The Supreme Court could well rule in a way that will make it harder for courts to throw out copyright claims on fair use grounds.
- In my view, everything about fair use is on the table in this case. Most commentary has focused on “transformative use” because it is a problematic concept that has come to dominate fair use analyses.
- But the subject matter at issue—the complex way a myriad of small, mostly invisible computer programs are organized—is very different from most types of copyrighted works. Generalizing from this unusual type of copyright to more familiar types might lead to unintended consequences.
-
How We Got Here
- Did you know Google has pretty much already won this case? No, not this issue (yet). But the whole case? Oracle sued Google mostly for patent infringement. This copyright claim was almost an afterthought. After a jury trial, the jury found for Google on the patent issues. Since patent claims are worth multiples of what copyright claims are worth, and Oracle had several patent claims, Google has already dodged about 90% of its potential liability. (I’ll have more to say about damages later.)
- This case has gone “up and down” twice. That is to say, it’s been appealed twice. The first time, the trial court threw out the copyright claim because it found the work at issue ( more on that in a moment) to be a “method of operation” and thus not protectable. On Oracle’s appeal, the Federal Circuit1Which normally hears appeals of patent cases, and heard this appeal even though the patent claims were long gone, because once a patent case, always a patent case, at least for appellate jurisdiction. reversed, correctly in my view (I’ll explain below). The case was sent back to the trial court, where a full-blown jury trial was held just on the issue of fair use. The jury found Google’s use was fair. Oracle appealed, and the Federal Circuit reversed again (incorrectly this time, in my view).
- Google appealed to the Supreme Court, which took the case (it didn’t have to). The Supreme Court has decided to consider two issues, one from each appeal. First, whether the work in question is a “method of operation” and thus not protectable. Second, whether the jury verdict of fair use should be reinstated.
- The Supreme Court doesn’t take very many copyright cases. This means copyright law tends to be fractured among the various circuits. So when it does, it’s a big deal for copyright lawyers. But be warned. Supreme Court decisions on copyright cases have historically been unpredictable and a little hard to understand and implement. I.e., instead of clearing things up, Supreme Court copyright decisions often makes things worse.
-
What They’re (Really) Fighting Over
- This case is about “Java.” It’s a programming language designed to work across platforms, i.e., its programs can work on different computer systems. Back in 1995, this was a very big deal. It was developed by Sun Microsystems, which was later acquired by Oracle. Before that acquisition, Sun had made almost all of Java open source so anyone could use it without a special license. But there was a catch: if you used the “free” license, you had to render back to the community your improvements and other modifications. Otherwise, you had to pay a licensing fee.
- Google didn’t want to pay what Oracle was asking for, so it set about re-inventing (as it were) Java in a way (it hoped) would avoid Oracle’s copyrights and patents. As we’ll see, it wasn’t 100% successful—more like 97% successful—but that missing 3% mattered a lot.
- You’ll hear that this case is about “APIs,” “application programming interfaces.” These are ubiquitous in computer programming. Indeed, computer programming wouldn’t be possible without them. They’re like little go-betweens, running from one software component or resource to another. In doing so, they perform the task they were programmed to do. To take a now-famous example from Java, “max,” you type in “max (x,y),” where “x” and “y” are integers, the max API will tell you which is bigger. That doesn’t sound like much, but that API can be incorporated into a more complex API, and so forth.
- Computers are simple-minded. You need to build up their complexity so they can interact with human beings. You start with a level of complexity that specialists can understand, they build up the complexity to the point that non-specialists can use the computer with ease.
- To take another example of an API. Google Maps and Twitter make APIs publicly available to website developers, so they can incorporate maps and Twitter feeds into a webpage. That’s often what people think about when they think about APIs.
- But the Java APIs at issue in Oracle v. Google aren’t so grand. They’re the more workaday kind, that make Java’s “virtual machine” go. As is usually the case with such APIs, there are a lot of them. If they are going to be useful to programmers, they’ll need to be organized in a way programmers can readily grasp.
- The parties are fighting over the way Java’s APIs are organized. Not the APIs themselves, and not any code per se. (More on that in a minute.) The organization of the Java API is very complicated! That’s not what makes it copyrightable—it’s more of a warning. Above is a small portion of that organization, courtesy of Oracle’s February 11, 2013 appellate brief (scroll down to page 25, fig. 2).
- Google reverse engineered the Java APIs themselves. Google knew what each API was supposed to do and generally how the APIs were programmed. So it was just a matter of hiring a bunch of folks to re-write the APIs from scratch, without reference to the original APIs. Remember, it’s not copyright infringement if you don’t actually copy.
- But Google kept the way the APIs were organized. As you’ll see, that organization is reflected in the content of each API. So, even though Google didn’t copy the APIs themselves, Google did copy the way the library of APIs were organized, and that copied organization necessarily was copied into Google’s version of the Java APIs.
-
Protecting the Organization of Things
- Copyright law does protect the organization of otherwise non-protectable things, like facts. There are limits to this protection, though. The organization can be neither arbitrary nor systematic. Court opinions about the copyrightability of parts catalogs are helpful. If the part numbers are random, there’s no protection because there’s no creativity. But many part numbers are themselves determined by information about the part, e.g., its type, material, year of manufacture, etc. That’s not protectable because all the part number does is encode non-protectable facts. To get protection on organization of non-protectable elements, you need to thread this needle.
- Java’s API Library threads this needle. Well, it does based on the underdeveloped record (more on that below). You can immediately tell it’s not arbitrary. At the same time, it doesn’t appear that the organization is determined by outside (non-protectable) factors, at least not to the untrained eye. For example, it might be apparent that java.security.KeyStore.PassswordProtection has something to do with Java, the security of information, the storage of encryption keys, and the protection of passwords, but that name wasn’t (necessarily) determined by anything we can tell. It’s descriptive, but not determinative.
-
Is This Really “Original”?
- Why did I keep qualifying myself in that last point? Because it’s quite possible that the organization was determined by outside (non-protectable) factors—in this case, convention. Sure, you don’t have to use “KeyStore.” Maybe you could’ve used “StoreKey,” or even “Banana.” But while “Banana” is silly because it communicates nothing, perhaps “StoreKey” would’ve confused other programmers, who would’ve been expecting “KeyStore.” Maybe “KeyStore” is a term of art, and whoever created the organization of the Java API library had no real choice but to use “KeyStore” or risk confusing those he or she wished to use Java. If so—and if this were true for the vast majority of the terms used in the organization of the Java API library—then Oracle’s copyright claim would fail for lack of originality. If there are only a few reasonable ways to express an idea, the (protectable) expression merges into the (non-protectable) idea and becomes non-protectable. This is known as the Merger Doctrine, but here, you can think of it as the author lacking enough room to maneuver to be creative.
- But that’s all speculation. Google would’ve needed to introduce—at trial—evidence that the myriad terms used in the organization of the Java API Library were conventional. Google didn’t. How could Google, with all its resources, overlook this? I direct your attention to my first point: the copyright claim was a side-show. Almost all effort was put toward defeating (successfully) the patent claims.
-
Isn’t This Just a “Method of Operation”?
- Are you surprised that copyright law can apply to the organization of API libraries, to say nothing of a system of parts numbers? It’s true: copyright protects a great many things that are a far cry from art and literature. It protects things like estimated used car prices, estimated prices of collectable coins, and “health grades,” provided those fact-like pieces of information were the result of some degree of subjectivity, evaluation and opinion.
- But doesn’t the Copyright Act explicitly exclude things like “procedures,” “processes,” “systems” and “method of operation”? Yes it does. And doesn’t the organization of an API library fall into one or more of these categories? Well…. So, let’s talk about Section 102(b), which where that language comes from. When Congress wrote and enacted Section 102(b), it intended to change nothing: “Section 102(b) in no way enlarges or contracts the scope of copyright protection under the present law. Its purpose is to restate, in the context of the new single Federal system of copyright, that the basic dichotomy between expression and idea remains unchanged.”
- But Congress also pointed out that it didn’t quite know how this “dichotomy” would apply to computer programs, only that it would, somehow. To be fair, this was 1976, and computer programming was still a fairly nascent field. It wasn’t even clear the Copyright Act would extend to computer programs (that would come two years later). “Section 102(b) is intended, among other things, to make clear that the expression adopted by the programmer is the copyrightable element in a computer program, and that the actual processes or methods embodied in the program are not within the scope of the copyright law.”
- Now, hitherto, computer programs have been treated much like—though not exactly like—any other “literary work.” After all, computer programs have a certain internal organization, which might or might not be protectable, but you can say the same thing about most novels. And, in both cases, there’s going to be a question about whether such an organization is too abstract, or too conventional, to be protected. This is accepted and not very controversial.
- But this is the Supreme Court, and the Supreme Court can turn this whole thing on its head. If you were to ignore the legal context and the Congressional intent, you might very well conclude that the organization of the Java library is just a system that is excluded from copyright protection by Section 102(b). There are some justices on the Court who believe quite strongly that statutes should mean what they say, not necessarily what Congress intended them to mean.
- The Supreme Court isn’t likely to read Section 102(b) this literally, but, boy, if it does, it’s going to be huge change in software law (and, you know, part number law).
-
What about Interoperability?
- One final point before getting into fair use. What about interoperability? First of all, interoperability is relevant only for fair use (about which, see below). Second of all, interoperability posits a pre-existing operating system or other system that the software has to work with. The classic case involved reverse engineering a console-game operating system so the game designer could make games that would work on that system. But, here, Java is the operating system. Google wasn’t just trying to make programs that work with Java. It was trying to duplicate Java because programmers were used to it. So, if nothing else, this isn’t a classic case of interoperability.
-
Boring But Important: Is Fair Use a Jury Question?
- OK, fair use, but first we have to talk about something very important but very boring. Who determines whether a use is fair or not: the judge or the jury? This is a crucial question because a jury found Google’s use of the organization of the Java library to be fair. And jury verdicts are supposed to be very hard to overturn. If there is any evidentiary basis for the jury verdict, the appellate court must let the verdict stand—even if the appellate court would have reached a different conclusion from the jury’s. So, if fair use is a jury question, Google should win, and Oracle should lose.
- Historically, lawyers and judges have viewed this question as a kind of paradox. They’ve assumed fair use is a jury question, yet is one that judges can determine early in the case (before a jury is involved). Fair use involves a lot of the kind of detailed factual questions typically left to juries, e.g., the existence of a market or potential market for the underlying work and whether the use in question affects that market or potential market. But fair use also implicates fundamental constitutional rights—your ability to use someone else’s work affects your ability to express yourself—which is the sort of thing left to judges because we like consistency (which juries are anything but). Weirdly, this question has simply never been squarely put before an appellate court before this case.
- The irony here is that, if Oracle prevails on this issue, it will strengthen fair use overall. Jury questions tend to go to the jury (duh), and juries don’t get involved until the trial. That means the defendant—i.e., the one arguing for fair use—would have to stay financially and emotionally afloat for 18 months or two years before a court can finally tell them if their use was fair or not. Large plaintiffs—the Disney’s of the world—can grind down defendants whose use is obviously fair just because no one can afford justice. But if fair use is not a jury question, then a judge can rule much earlier in the case—sometimes at the very beginning of the case.
-
Who Cares if it’s a Jury Question? Didn’t Oracle Consent to a Jury Trial?
- But wait! There’s something we need to resolve before we can get to this judge-jury thing. Regardless of whether fair use should have been determined by a jury, didn’t Oracle kind of agree to have a jury decide the question? Rule 39(c)(2) provides that, even if an issue shouldn’t be tried by a jury, it still can be, if the parties “consent.”
- There’s not a ton of caselaw on this, but usually, if you let a non-jury issue be decided by a jury without objecting, you’re deemed to have consented. I guess this is because it’s wasteful of everyone’s time and resources to have to re-try a case, and to discourage gaming the system.
- What’s weird is that Google isn’t pushing this at all—and neither have any of its supporters. So I must be the crazy one.
-
Finally, Fair Use
- OK, fair use, for real this time. There are four factors: (1) purpose and character of the use, (2) nature of the copyrighted work, (3) amount and substantiality of the portion taken, (4) effect of the use on the actual and potential market for the copyrighted work. Factors (1) and (4) are considered the most important. There’s been a trend to read factor (2) out of existence.
-
Transformative Use: The Genie Out of its Bottle
- And, before we can even get started, we’re derailed by something called “transformative use.” That’s what everyone wants to talk about. “Transformative use” is a concept invented by a judge who has authored many important copyright decisions named Leval. He intended it to be a principled way to think about the first factor. In this respect, he failed utterly. Not his fault, but, in practice, “transformative use” has been anything but principled. It’s so unprincipled that I can barely explain it anymore.
- Here is how Judge Leval described “transformative use” when he first invented the concept back in 1990:
-
If, on the other hand, the secondary use adds value to the original—if the quoted matter is used as raw material, transformed in the creation of new information, new aesthetics, new insights and understandings—this is the very type of activity that the fair use doctrine intends to protect for the enrichment of society. Transformative uses may include criticizing the quoted work, exposing the character of the original author, proving a fact, or summarizing an idea argued in the original in order to defend or rebut it.
- So a mashup of two pre-existing works. Or making a new work out of the pre-existing work, like cutting it up and making a collage. Perhaps even using a copyrighted photograph that documents an important historical event in a history book about that event.
- But the transformative genie has long since gotten out of its bottle. It is often the only significant factor in fair use analyses. Worse, it’s seen as having a kind of on-off switch: either the use is transformative, in which case it’s almost certainly fair; or it’s not, in which case it almost certainly is not. In my view, these are both mistakes.
- A lot of people would like to put transformative genie back into its bottle. They see Oracle v. Google as the opportunity. The reason is that Google has made a fairly weak attempt at arguing for transformative use. It goes something like this: yes, we took the organization of the Java library, but look, we made a really cool Android mobile operating system out of it. My own sense is that’s not nothing, but it’s hardly what Judge Leval had in mind.
- To my mind, there’s a more fundamental problem with “transformative use” as applied to this case (as opposed to generally). How does one “transform” computer code? Computer code is primarily functional. It does not “mean” very much beyond what it “does.” Even if you radically re-purposed someone else’s code, you haven’t changed its meaning.
- This leads to two conclusions: (1) this case might not be the best case to put the transformative genie back in the bottle, and (2) we might need to reconsider how fair use is applied to computer programs generally. It is exceptionally odd (and wrong) that computer programs should be effectively immune to fair uses simply because they can’t be “transformed.”
-
It’s the Second Factor’s Time to Shine
- The answer, in my view, is to look at the other factors, most notably the much-denigrated second factor: the nature of the copyrighted work. Historically, this has looked to the creativity of the underlying work: the more creative, the less likely the use is fair. This case shows why this factor is still relevant. Only now does it hit you that this case is solely about the way somebody named and organized a bunch of APIs. Not the APIs themselves. Not the code itself (more on that in a moment). The organization.
- The bar for being eligible for copyright protection is low, almost laughably low. And in many respects, once you clear that low bar, your copyright is as good and as strong as any other copyright. But when it comes to socially productive uses of underlying works, it makes sense that we’ll treat, say, the way replacement parts are numbered and organized differently from the way we treat, say, Bel Canto2I haven’t actually read this. I’m just making a Nashville reference regarding the owner of Parnassus Books.. One is much closer to the fundamental purpose of copyright law than the other. It also serves to counterbalance the fact that it’s much harder to “transform” uncreative but protectable works.
-
The Third Factor: Focus on What Was (Really) Taken
- Moving to the third factor—amount and substantiality of the copyrighted work used—you’ll hear Oracle and its supports say that Google has appropriated some many thousands of lines of code. And this is true. And it’s meaningless. The code that Google has copied is nothing more than a reflection of the organization of the Java API library, which itself is just a small and only incidentally significant portion of the Java APIs at issue.
- To understand that, you need to understand that each API that Google is accused of misappropriating consists of two types of code: declaring code and implementing code. The declaring code states where in the API organization the API may be found. The real action is in the implementing code, which tells you what to do. Google was able to legally reverse-engineer the implementing code.
- Crucially, the declaring code repeats—encapsulates—the hierarchical information inherent in the API. If the API is located within the library at java.security.KeyStore.PassswordProtection3There might be one more level to this particular hierarchy, so: java.security.KeyStore.PassswordProtection.method., then the declaring code for that API will state “java.security.KeyStore.PassswordProtection.” As Oracle persuasively argued, what creativity there is in the declaring code lies in the way the Java API library is organized:
-
Because declaring code identifies, specifies, and defines the components and their arrangement within the packages, when Google copied Java’s declaring code, it also copied the ‘sequence and organization’ of the packages…
- This argument was key to Oracle’s victory in the first appeal.
-
Fourth Factor: At Least Oracle Tried
- Onto the fourth factor! We’re almost done! This is conceptually the easiest factor, but it’s also the hardest factor to apply. It’s conceptually easy because the point of copyright law is to protect markets for creative works. If you can show the infringing work is actively hurting your ability to sell your work, the use shouldn’t be fair. But it also protects potential markets. Just because you’re creative doesn’t mean you’re especially good at business, i.e., finding, developing and exploiting markets. You shouldn’t be penalized just because the infringer is better at exploiting markets than you. At the same time, the eventual beneficiary of copyright is the public because it produces delightful creative works. But if those works can’t get to the public…
- Here, Oracle actually tried to market Java as an operating system, even a mobile one. Its efforts were pretty much complete failures. How does that affect your weighting of the fourth factor? In my own view, it weighs against fair use, but only a little. In the Federal Circuit’s view, it weighed heavily against fair use, because, to the Federal Circuit, any market harm is enough to have this factor weigh heavily, even decisively, against fair use.
-
Conclusion: A Unanimous Decision on Narrow Grounds, Please
- In my view, this is a rare case in which fair use comes down to the second and third factors. So, I’d agree with the 12 jurors who found fair use.
- Oracle v. Google is an unusual copyright case, so it might not be the best case to establish general principles of copyright law. It’s a case about “methods of operation” in the context of a functional work. It’s about “transformative use” in the context of work that can’t really be transformed. I fear almost anything the Supreme Court comes up with, to be honest. I wish the Court could just say Oracle consented to that jury and there’s enough to support the jury verdict, now go home.
- Thank you for reading!
Footnotes
| ↑1 | Which normally hears appeals of patent cases, and heard this appeal even though the patent claims were long gone, because once a patent case, always a patent case, at least for appellate jurisdiction. |
|---|---|
| ↑2 | I haven’t actually read this. I’m just making a Nashville reference regarding the owner of Parnassus Books. |
| ↑3 | There might be one more level to this particular hierarchy, so: java.security.KeyStore.PassswordProtection.method. |
